Object类是java中所有类的父类,所有类默认(而非显式)继承Object。这也就意味着,Object类中的所有公有方法也将被任何类所继承。如果,整个java类体系是一颗树,那么Object类毫无疑问就是整棵树的根。
jdk版本:1.8
整体分析
1 | public class Object { |
方法解释
public boolean equals(Object obj)
== 与equals在Java中经常被使用,大家也都知道==与equals的区别:==表示的是变量值完成相同(对于基础类型,地址中存储的是值,引用类型则存储指向实际对象的地址);
equals表示的是对象的内容完全相同,此处的内容多指对象的特征/属性。
实际上,上面说法是不严谨的,更多的只是常见于String类中。首先看一下Object类中关于equals()方法的定义:
1 | public boolean equals(Object obj) { |
由此可见,Object原生的equals()方法内部调用的正是==,与==具有相同的含义。既然如此,为什么还要定义此equals()方法?
equlas()方法的正确理解应该是:判断两个对象是否相等。 那么判断对象相等的标尺又是什么?
如上,在object类中,此标尺即为==。当然,这个标尺不是固定的,其他类中可以按照实际的需要对此标尺含义进行重定义。如String类中则是依据字符串内容是否相等来重定义了此标尺含义。如此可以增加类的功能型和实际编码的灵活性。当然了,如果自定义的类没有重写equals()方法来重新定义此标尺,那么默认的将是其父类的equals(),直到object基类。
public native int hashCode()
hashCode()方法返回一个整形数值,表示该对象的哈希码值。
hashCode()具有如下约定:
- 在Java应用程序程序执行期间,对于同一对象多次调用hashCode()方法时,其返回的哈希码是相同的,前提是将对象进行equals比较时所用的标尺信息未做修改。在Java应用程序的一次执行到另外一次执行,同一对象的hashCode()返回的哈希码无须保持一致;
- 如果两个对象相等(依据:调用equals()方法),那么这两个对象调用hashCode()返回的哈希码也必须相等;
- 反之,两个对象调用hasCode()返回的哈希码相等,这两个对象不一定相等。
在此需要纠正一个理解上的误区:对象的hashCode()返回的不是对象所在的物理内存地址。甚至也不一定是对象的逻辑地址,hashCode()相同的两个对象,不一定相等,换言之,不相等的两个对象,hashCode()返回的哈希码可能相同。
public String toString()
toString()方法返回该对象的字符串表示。先看一下Object中的具体方法体:
1 | public String toString() { |
- getClass()返回对象的类对象,getClassName()以String形式返回类对象的名称(含包名)。
- Integer.toHexString(hashCode())则是以对象的哈希码为实参,以16进制无符号整数形式返回此哈希码的字符串表示形式。
toString()是由对象的类型和其哈希码唯一确定,同一类型但不相等的两个对象分别调用toString()方法返回的结果可能相同。
protected void finalize()
finalize方法主要与Java垃圾回收机制有关。首先我们看一下finalized方法在Object中的具体定义:
1 | protected void finalize() throws Throwable { } |
我们发现Object类中finalize方法被定义成一个空方法,为什么要如此定义呢?finalize方法的调用时机是怎么样的呢?
首先,Object中定义finalize方法表明Java中每一个对象都将具有finalize这种行为,任何类都是重写finalize方法,实现自己想要的功能。其具体调用时机在:JVM准备对此对象所占用的内存空间进行垃圾回收前,将被调用。由此可以看出,此方法并不是由我们主动去调用的(虽然可以主动去调用,此时与其他自定义方法无异)。
finalize的作用
finalize()是Object的protected方法,子类可以覆盖该方法以实现资源清理工作,GC在回收对象之前调用该方法。
finalize()与C++中的析构函数不是对应的。C++中的析构函数调用的时机是确定的(对象离开作用域或delete掉),但Java中的finalize的调用具有不确定性。
不建议用finalize方法完成“非内存资源”的清理工作,但建议用于:
- 清理本地对象(通过JNI创建的对象);
- 作为确保某些非内存资源(如Socket、文件等)释放的一个补充:在finalize方法中显式调用其他资源释放方法。
finalize的问题
- 一些与finalize相关的方法,由于一些致命的缺陷,已经被废弃了,如System.runFinalizersOnExit()方法、Runtime.runFinalizersOnExit()方法。
- System.gc()与System.runFinalization()方法增加了finalize方法执行的机会,但不可盲目依赖它们。
- Java语言规范并不保证finalize方法会被及时地执行、而且根本不会保证它们会被执行。
finalize方法可能会带来性能问题。因为JVM通常在单独的低优先级线程中完成finalize的执行。 - 对象再生问题:finalize方法中,可将待回收对象赋值给GC Roots可达的对象引用,从而达到对象再生的目的。
- finalize方法至多由GC执行一次(用户当然可以手动调用对象的finalize方法,但并不影响GC对finalize的行为)。
finalize的执行过程(生命周期)
1. finalize大体流程
当对象变成(GC Roots)不可达时,GC会判断该对象是否覆盖了finalize方法,若未覆盖,则直接将其回收。否则,若对象未执行过finalize方法,将其放入F-Queue队列,由一低优先级线程执行该队列中对象的finalize方法。执行finalize方法完毕后,GC会再次判断该对象是否可达,若不可达,则进行回收,否则,对象“复活”。
2. 具体的finalize流程
对象可由两种状态,涉及到两类状态空间,一是终结状态空间 F = {unfinalized, finalizable, finalized};二是可达状态空间 R = {reachable, finalizer-reachable, unreachable}。各状态含义如下:
- unfinalized:新建对象会先进入此状态,GC并未准备执行其finalize方法,因为该对象是可达的;
- finalizable:表示GC可对该对象执行finalize方法,GC已检测到该对象不可达。正如前面所述,GC通过F-Queue队列和一专用线程完成finalize的执行;
- finalized:表示GC已经对该对象执行过finalize方法;
- reachable:表示GC Roots引用可达;
- finalizer-reachable(f-reachable):表示不是reachable,但可通过某个finalizable对象可达;
- unreachable:对象不可通过上面两种途径可达。
状态变迁图:
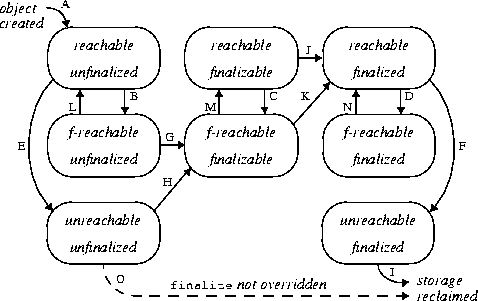
变迁说明:
- 新建对象首先处于[reachable, unfinalized]状态(A);
- 随着程序的运行,一些引用关系会消失,导致状态变迁,从reachable状态变迁到f-reachable(B, C, D)或unreachable(E, F)状态;
- 若JVM检测到处于unfinalized状态的对象变成f-reachable或unreachable,JVM会将其标记为finalizable状态(G,H)。若对象原处于[unreachable, unfinalized]状态,则同时将其标记为f-reachable(H);
- 在某个时刻,JVM取出某个finalizable对象,将其标记为finalized并在某个线程中执行其finalize方法。由于是在活动线程中引用了该对象,该对象将变迁到(reachable, finalized)状态(K或J)。该动作将影响某些其他对象从f-reachable状态重新回到reachable状态(L, M, N);
- 处于finalizable状态的对象不能同时是unreahable的,由第d点可知,将对象finalizable对象标记为finalized时会由某个线程执行该对象的finalize方法,致使其变成reachable。这也是图中只有八个状态点的原因;
- 程序员手动调用finalize方法并不会影响到上述内部标记的变化,因此JVM只会至多调用finalize一次,即使该对象“复活”也是如此。程序员手动调用多少次不影响JVM的行为;
- 若JVM检测到finalized状态的对象变成unreachable,回收其内存(I);
- 若对象并未覆盖finalize方法,JVM会进行优化,直接回收对象(O);
- 注:System.runFinalizersOnExit()等方法可以使对象即使处于reachable状态,JVM仍对其执行finalize方法。
wait/notify/notifyAll
wait()
1 | public final void wait() throws InterruptedException { |
该方法用来将当前线程置入休眠状态,直到接到通知或被中断为止。在调用wait()之前,线程必须要获得该对象的对象级别锁,即只能在同步方法或同步块中调用wait()方法。进入wait()方法后,当前线程释放锁。在从wait()返回前,线程与其他线程竞争重新获得锁。如果调用wait()时,没有持有适当的锁,则抛出IllegalMonitorStateException,它是RuntimeException的一个子类,因此,不需要try-catch结构。
notify()
1 | public final native void notify(); |
该方法也要在同步方法或同步块中调用,即在调用前,线程也必须要获得该对象的对象级别锁,如果调用notify()时没有持有适当的锁,也会抛出IllegalMonitorStateException。
该方法用来通知那些可能等待该对象的对象锁的其他线程。如果有多个线程等待,则线程规划器任意挑选出其中一个wait()状态的线程来发出通知,并使它等待获取该对象的对象锁(notify后,当前线程不会马上释放该对象锁,wait所在的线程并不能马上获取该对象锁,要等到程序退出synchronized代码块后,当前线程才会释放锁,wait所在的线程也才可以获取该对象锁),但不惊动其他同样在等待被该对象notify的线程们。当第一个获得了该对象锁的wait线程运行完毕以后,它会释放掉该对象锁,此时如果该对象没有再次使用notify语句,则即便该对象已经空闲,其他wait状态等待的线程由于没有得到该对象的通知,会继续阻塞在wait状态,直到这个对象发出一个notify或notifyAll。这里需要注意:它们等待的是被notify或notifyAll,而不是锁。这与下面的notifyAll()方法执行后的情况不同。
notifyAll()
1 | public final native void notifyAll(); |
该方法与notify()方法的工作方式相同,重要的一点差异是:
notifyAll使所有原来在该对象上wait的线程统统退出wait的状态(即全部被唤醒,不再等待notify或notifyAll,但由于此时还没有获取到该对象锁,因此还不能继续往下执行),变成等待获取该对象上的锁,一旦该对象锁被释放(notifyAll线程退出调用了notifyAll的synchronized代码块的时候),他们就会去竞争。如果其中一个线程获得了该对象锁,它就会继续往下执行,在它退出synchronized代码块,释放锁后,其他的已经被唤醒的线程将会继续竞争获取该锁,一直进行下去,直到所有被唤醒的线程都执行完毕。
wait(long)和wait(long,int)
1 | public final native void wait(long timeout) throws InterruptedException; |
显然,这两个方法是设置等待超时时间的,后者在超值时间上加上ns,精度也难以达到,因此,该方法很少使用。对于前者,如果在等待线程接到通知或被中断之前,已经超过了指定的毫秒数,则它通过竞争重新获得锁,并从wait(long)返回。另外,需要知道,如果设置了超时时间,当wait()返回时,我们不能确定它是因为接到了通知还是因为超时而返回的,因为wait()方法不会返回任何相关的信息。但一般可以通过设置标志位来判断,在notify之前改变标志位的值,在wait()方法后读取该标志位的值来判断,当然为了保证notify不被遗漏,我们还需要另外一个标志位来循环判断是否调用wait()方法。
深入理解:
如果线程调用了对象的wait()方法,那么线程便会处于该对象的等待池中,等待池中的线程不会去竞争该对象的锁。
当有线程调用了对象的notifyAll()方法(唤醒所有wait线程)或 notify())方法(只随机唤醒一个wait线程),被唤醒的的线程便会进入该对象的锁池中,锁池中的线程会去竞争该对象锁。
优先级高的线程竞争到对象锁的概率大,假若某线程没有竞争到该对象锁,它还会留在锁池中,唯有线程再次调用wait()方法,它才会重新回到等待池中。而竞争到对象锁的线程则继续往下执行,直到执行完了synchronized代码块,它会释放掉该对象锁,这时锁池中的线程会继续竞争该对象锁。
补充问题
1. 为何调用wait方法有可能抛出InterruptedException异常?
这个异常大家应该都知道,当我们调用了某个线程的interrupt方法时,对应的线程会抛出这个异常,wait方法也不希望破坏这种规则,因此就算当前线程因为wait一直在阻塞,当某个线程希望它起来继续执行的时候,它还是得从阻塞态恢复过来,因此wait方法被唤醒起来的时候会去检测这个状态,当有线程interrupt了它的时候,它就会抛出这个异常从阻塞状态恢复过来。
这里有两点要注意:
- 如果被interrupt的线程只是创建了,并没有start,那等他start之后进入wait态之后也是不能会恢复的
- 如果被interrupt的线程已经start了,在进入wait之前,如果有线程调用了其interrupt方法,那这个wait等于什么都没做,会直接跳出来,不会阻塞。
2. wait的线程是否会影响系统加载降低性能?
这个或许是大家比较关心的话题,因为关乎系统性能问题,wait/nofity是通过jvm里的park/unpark机制来实现的,在linux下这种机制又是通过pthread_cond_wait/pthread_cond_signal来玩的,因此当线程进入到wait状态的时候其实是会放弃cpu的,也就是说这类线程是不会占用cpu资源,也不会影响系统加载。
3. 为什么wait(),notify()方法要和synchronized一起使用?
因为wait()方法是通知当前线程等待并释放对象锁,notify()方法是通知等待此对象锁的线程重新获得对象锁,然而,如果没有获得对象锁,wait方法和notify方法都是没有意义的,即必须先获得对象锁,才能对对象锁进行操作,于是,才必须把notify和wait方法写到synchronized方法或是synchronized代码块中了。
protected native Object clone() throws CloneNotSupportedException
Java中对象的创建
clone顾名思义就是复制, 在Java语言中, clone方法被对象调用,所以会复制对象。所谓的复制对象,首先要分配一个和源对象同样大小的空间,在这个空间中创建一个新的对象。那么在java语言中,有几种方式可以创建对象呢?
- 使用new操作符创建一个对象
- 使用clone方法复制一个对象
那么这两种方式有什么相同和不同呢? new操作符的本意是分配内存。程序执行到new操作符时, 首先去看new操作符后面的类型,因为知道了类型,才能知道要分配多大的内存空间。分配完内存之后,再调用构造函数,填充对象的各个域,这一步叫做对象的初始化,构造方法返回后,一个对象创建完毕,可以把他的引用(地址)发布到外部,在外部就可以使用这个引用操纵这个对象。而clone在第一步是和new相似的, 都是分配内存,调用clone方法时,分配的内存和源对象(即调用clone方法的对象)相同,然后再使用原对象中对应的各个域,填充新对象的域, 填充完成之后,clone方法返回,一个新的相同的对象被创建,同样可以把这个新对象的引用发布到外部。
复制对象和复制引用
在Java中,以下类似的代码非常常见:
1 | Person person1 = new Person(18, "tony"); |
执行结果:
1 | com.prowo.jdk.clone.Person@3c679bde |
可已看出,打印的地址值是相同的,既然地址都是相同的,那么肯定是同一个对象。person1和person2只是引用而已,他们都指向了一个相同的对象Person(18, “tony”)。 可以把这种现象叫做引用的复制。
而下面的代码是真真正正的克隆了一个对象。
1 | Person person1 = new Person(18, "tony"); |
从打印结果可以看出,两个对象的地址是不同的,也就是说创建了新的对象, 而不是把原对象的地址赋给了一个新的引用变量:
1 | com.prowo.jdk.clone.Person@3c679bde |
浅克隆和深克隆
上面的示例代码中,Person中有两个成员变量,分别是name和age, name是String类型, age是int类型。代码非常简单,如下所示:
1 | public class Person implements Cloneable { |
由于age是基本数据类型, 那么对它的拷贝没有什么疑议,直接将一个4字节的整数值拷贝过来就行。但是name是String类型的, 它只是一个引用, 指向一个真正的String对象,那么对它的拷贝有两种方式: 直接将源对象中的name的引用值拷贝给新对象的name字段, 或者是根据原Person对象中的name指向的字符串对象创建一个新的相同的字符串对象,将这个新字符串对象的引用赋给新拷贝的Person对象的name字段。这两种拷贝方式分别叫做浅拷贝和深拷贝。
下面通过代码进行验证。如果两个Person对象的name的地址值相同, 说明两个对象的name都指向同一个String对象, 也就是浅拷贝, 而如果两个对象的name的地址值不同, 那么就说明指向不同的String对象, 也就是在拷贝Person对象的时候, 同时拷贝了name引用的String对象, 也就是深拷贝。验证代码如下:
1 | Person person1 = new Person(18, "tony"); |
所以,clone方法执行的是浅拷贝, 在编写程序时要注意这个细节。
浅克隆
在浅克隆中,如果原型对象的成员变量是值类型,将复制一份给克隆对象;如果原型对象的成员变量是引用类型,则将引用对象的地址复制一份给克隆对象,也就是说原型对象和克隆对象的成员变量指向相同的内存地址。
简单来说,在浅克隆中,当对象被复制时只复制它本身和其中包含的值类型的成员变量,而引用类型的成员对象并没有复制。
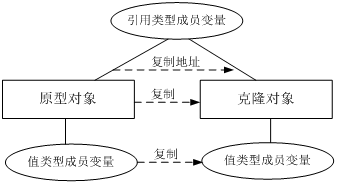
在Java语言中,通过覆盖Object类的clone()方法可以实现浅克隆。
深克隆
在深克隆中,无论原型对象的成员变量是值类型还是引用类型,都将复制一份给克隆对象,深克隆将原型对象的所有引用对象也复制一份给克隆对象。
简单来说,在深克隆中,除了对象本身被复制外,对象所包含的所有成员变量也将复制。
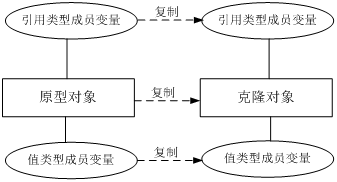
在Java语言中,如果需要实现深克隆,可以通过覆盖Object类的clone()方法实现,也可以通过序列化(Serialization)等方式来实现。
(如果引用类型里面还包含很多引用类型,或者内层引用类型的类里面又包含引用类型,使用clone方法就会很麻烦。这时我们可以用序列化的方式来实现对象的深克隆。)
序列化就是将对象写到流的过程,写到流中的对象是原有对象的一个拷贝,而原对象仍然存在于内存中。通过序列化实现的拷贝不仅可以复制对象本身,而且可以复制其引用的成员对象,因此通过序列化将对象写到一个流中,再从流里将其读出来,可以实现深克隆。需要注意的是能够实现序列化的对象其类必须实现Serializable接口,否则无法实现序列化操作。
扩展:
Java语言提供的Cloneable接口和Serializable接口的代码非常简单,它们都是空接口,这种空接口也称为标识接口,标识接口中没有任何方法的定义,其作用是告诉JRE这些接口的实现类是否具有某个功能,如是否支持克隆、是否支持序列化等。
解决多层克隆问题
如果引用类型里面还包含很多引用类型,或者内层引用类型的类里面又包含引用类型,使用clone方法就会很麻烦。这时我们可以用序列化的方式来实现对象的深克隆。
1 | public class Outer implements Serializable{ |
Inner也必须实现Serializable,否则无法序列化:
1 | public class Inner implements Serializable{ |
这样也能使两个对象在内存空间内完全独立存在,互不影响对方的值。
2.6.5 总结
实现对象克隆有两种方式:
- 实现Cloneable接口并重写Object类中的clone()方法;
- 实现Serializable接口,通过对象的序列化和反序列化实现克隆,可以实现真正的深度克隆。
注意: 基于序列化和反序列化实现的克隆不仅仅是深度克隆,更重要的是通过泛型限定,可以检查出要克隆的对象是否支持序列化,这项检查是编译器完成的,不是在运行时抛出异常,这种是方案明显优于使用Object类的clone方法克隆对象。让问题在编译的时候暴露出来总是优于把问题留到运行时。